近期工作中学到的一些 SQL 技巧
SQL 一直是我的弱项,在以往的开发中和 SQL 打交道实在有限。借着近期项目,尝试将尽量多的操作放在 SQL 中(而非返回到编程语言中)确实很好玩。以下是以 MySQL 为例。
新增数据后返回主键 ID
一种方法是使用数据库内置的 LAST_INSERT_ID() 函数:
insert into foo() values();
select LAST_INSERT_ID();
另一种办法是在 Java 里,创建 PreparedStatement 的时候就指定好(通过 Connection.prepareStatement(String, int) API),执行后再调用 Statement.getGeneratedKeys() API
PreparedStatement p = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
p.executeUpdate();
ResultSet r = p.getGeneratedKeys();
从其他表借用数据
insert into tb_1(col1)
select t2.col1
from tb_2 t2;
SQL JOIN
JOIN 很强大,可以串联多个 JOIN 语句。灵活也就意为着使用的时候需要更加小心。作为初学者这个图很有用,盗来一用。
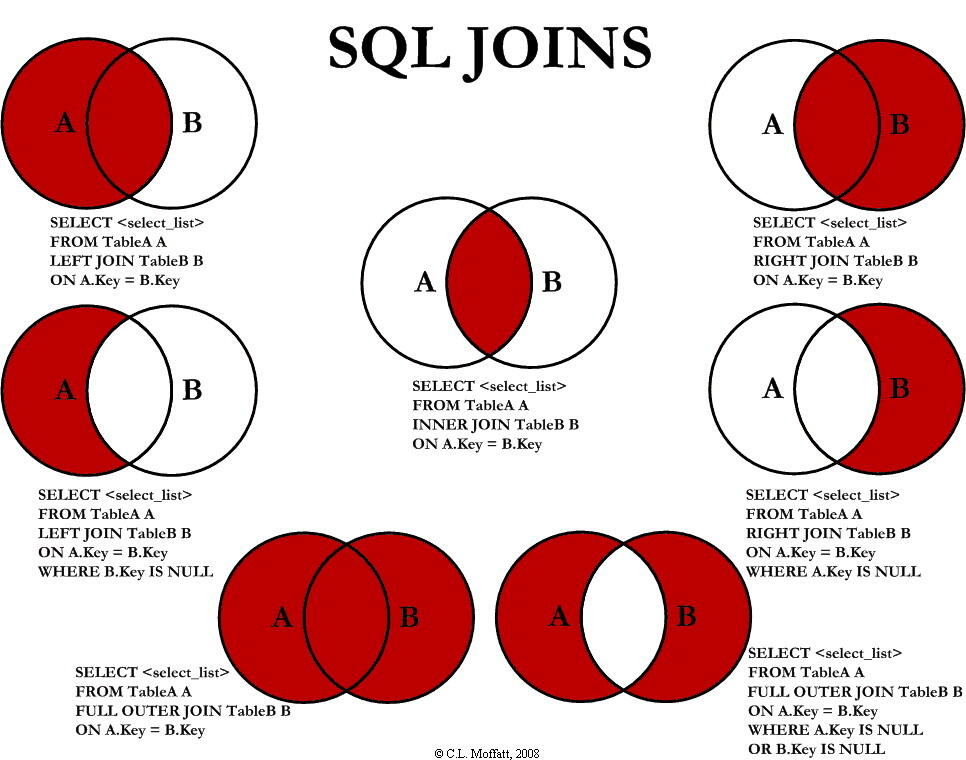
重复数据的处理
来自 leetcode #182、#196。特别是 196 删除重复的数据,在借鉴了 Stack Overflow 的一些回答后这里是我的写法,算是完成了任务,效率方面说比 76% 的提交要快,还没时间看别人的实现。
-- 182. Duplicate Emails.
select email from person group by email HAVING count(email) > 1;
-- 196. Delete Duplicate Emails.
delete person
from person
inner join (
select min(id) as firstid, email
from person
where email in (
select email from person
group by email
having count(*) > 1
)
group by email
) duplic on duplic.email = person.email
where person.id > duplic.firstid;
另外 having 和 where 的区别:where 不能用于 aggregate functions,常见的函数:
averagecountmaximummedianminimummoderangesum
其他
- Compiling C to WebAssembly without Emscripten - Emscripten 其实是一个 toolchain,包含 Node.js 等一堆的内容,其实将源码从 C 编译为 WASM 仅仅需要 llvm 以及其他的少数工具。作者 Surma 在文章中给出了比较详细的方案。
- algorithm-visualizer - 正如其名,算法可视化工具。
上个月实在是忙,草稿托了一个月,其实暂时用不上 WebAssembly 了,以后再关注。
